

Imagine this: you’re using your phone to transcribe a live conversation while snapping photos of handwritten notes, and it’s all happening instantly—without an internet connection. No lag, no cloud processing, just your device doing it all. That’s the kind of future Google’s Gemma 3n is building—except it’s not the future anymore. It’s here.

Gemma 3n is a compact, multimodal AI model designed to run efficiently on edge devices—meaning hardware like mobile phones, embedded systems, or laptops. It supports text, audio, and vision inputs, making it a versatile choice for developers building smart applications that work locally and offline. While there aren’t commercial mobile apps using Gemma 3n just yet, it’s built to support that kind of use in the near future.
In this article, we’ll walk through:
- What Gemma 3n is and how it fits into the AI landscape
- How it works—its core architecture and processing pipeline
- Real-world use cases, especially for developers targeting edge devices
- How to get started, including a basic code example and useful links
- And finally, a quick summary of why this model matters, and where to go next
Whether you’re a developer, researcher, or someone exploring on-device AI, this article will help you understand what Gemma 3n offers and why it matters.
What is Gemma 3n and Where It Fits in the AI World?
Gemma 3n is Google’s latest move into on-device AI — and it’s making waves. Launched on June 26, 2025, this model is part of the Gemma family, but with a major twist: it’s designed to run directly on your device, not just in the cloud. That means you can access smart AI features without needing a constant internet connection.
Gemma 3n is lightweight, multimodal, and optimized for edge devices, like smartphones, laptops, and even AR glasses. It’s meant for developers who want to build intelligent, fast, and privacy-focused apps that don’t rely heavily on remote servers.
Key Features of Gemma 3n:
- Audio input: Understands speech and can transcribe or translate spoken language on the fly.
- Vision input: Uses a MobileNet-V5 encoder for quick image recognition and understanding.
- Text input/output: Supports chat-style responses, ideal for virtual assistants or in-app conversations.
- Multimodal capabilities: Handles video, images, text, and even interleaved inputs (like a video with spoken and written content).
- Optimized for devices:
- Comes in two size variants:
- E2B (around 2 GB RAM usage)
- E4B (around 3 GB RAM usage)
- Both are built for performance, with around 5–8 billion effective parameters, giving strong capabilities without draining battery or memory.
- Comes in two size variants:
Core Architecture & Workflow
MatFormer & PLE
At the heart of Gemma 3n lies the MatFormer—short for Matryoshka Transformer. Imagine nested dolls: a big model contains a smaller, fully capable sub-model inside. Google trains the 8B‑parameter E4B model and the 5B‑parameter E2B model together so they share weights. You can load either E2B or the full E4B—or even mix sizes in between—for a flexible balance of performance and speed.
This nesting enables elastic execution: although not live in the first release, future versions may let the model automatically switch between E2B and E4B paths depending on device load.
Complementing MatFormer is Per‑Layer Embeddings (PLE). PLE stores large embedding tables separately and feeds them into each transformer layer as needed, but keeps them off the GPU—on CPU or disk. That way, only the core transformer weights occupy VRAM. This clever split allows E2B to run with ~2 GB of GPU memory and E4B with ~3 GB, even though they contain 5B and 8B parameters respectively.
On‑Device Optimization
One of Gemma 3n’s priorities is minimizing memory use while staying capable:
- Memory footprints:
- E2B (~5B parameters): ~2 GB GPU memory.
- E4B (~8B parameters): ~3 GB GPU memory .
- Activation quantization: Two new modules—AltUp and LAuReL—quantize activation layers to reduce precision demands without sacrificing quality. AltUp efficiently upsamples activations, while LAuReL (Learned Augmented Residual Layer) introduces flexible gating in transformer feeds, further trimming compute and memory needs.
All combined, these trade-offs enable Gemma 3n to deliver turbo-like performance without needing bulky hardware.
Input Pipeline
Gemma 3n is fully multimodal—handling text, audio, and images:
- Tokenization & Encoding
- Text: Standard subword tokenization, up to 32K tokens.
- Audio: An audio encoder (based on Universal Speech Model) produces a token every ~160 ms (~6.25 tokens/sec). Works for ASR and speech-to-text translation.
- Image/video: A fast MobileNet‑V5‑300M vision encoder processes 256×256 to 768×768 frames at up to 60 fps, embedding them for downstream fusion.
- Multimodal Fusion & Generation
- Token streams merge and flow into the MatFormer transformer.
- KV Cache Sharing accelerates long-context inputs (like audio or video): shared key-value states cut prefill time in half compared to Gemma 3 4B.
- The model decodes tokens autoregressively, seamlessly handling interactions across modes (e.g. text and image queries).
Benchmark Review: How Does It Perform?
Here’s how the two sizes of Gemma 3n stack up against rivals on a range of tasks:
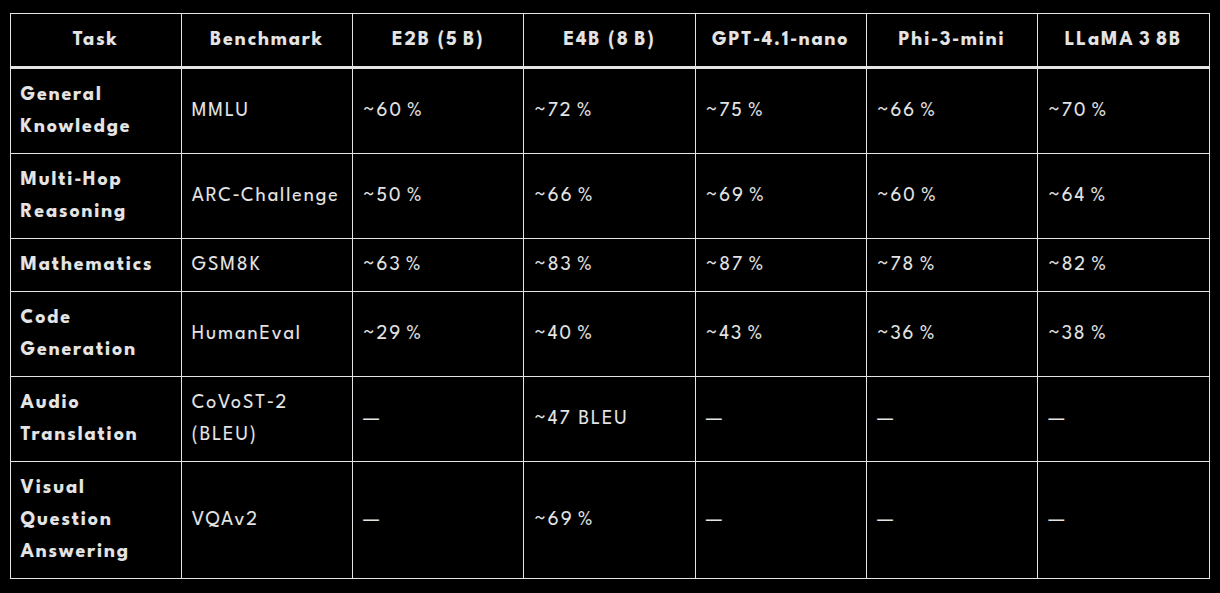
Note: “—” denotes tasks not publicly reported or modalities the model doesn’t support.
What This Means
- Top of the class: E4B is the first under‑10 B‑parameter model to clear 1300 Elo on LMArena—solid proof of its balanced skill set.
- Near‑state‑of‑the‑art: Against GPT‑4.1‑nano, E4B trails by only a few percentage points on knowledge, reasoning, and math—yet demands far less memory and compute.
- Speed vs. precision: The smaller E2B runs about 2× faster and uses significantly less RAM, but accuracy dips by 10–15 % across tasks.
Real‑World Use Cases
Gemma 3n isn’t just powerful in theory — it’s already making a difference in real-world applications. Thanks to its efficient, edge-friendly design, Gemma 3n can handle complex tasks right on your device, without needing to constantly ping the cloud. Here are a few ways developers are putting it to work:
Live Meeting Transcription & Translation
Gemma 3n can listen to live conversations, transcribe them in real time, and even translate the text into different languages. This is perfect for international meetings, interviews, or live events where fast, accurate translation is key.
Offline Photo Analysis
Whether it’s recognizing objects in a picture or generating a quick caption, Gemma 3n can analyze images entirely offline. This is useful for privacy-focused apps, travel tools, or any situation where internet access is limited.
Multimodal Chatbots
Gemma 3n supports both text and image inputs, making it ideal for smarter chatbots that can understand and respond to visual queries — like a user sending a photo and asking a question about it.
Video Captioning & Summarization
Developers can use Gemma 3n to generate captions for videos or summarize long clips into quick overviews. This can be helpful for media apps, educational content, or accessibility tools.
Accessibility Tools
From generating image descriptions for the visually impaired to offering real-time voice transcription, Gemma 3n is helping make technology more inclusive. Because it runs locally, it’s fast, private, and works even in low-connectivity environments.
Benefits & Challenges
Benefits
- Real‑time, offline inference
Gemma 3n processes audio, images, text, and video entirely on-device, without needing internet—ideal for privacy-focused or connectivity-limited use cases. - Low memory footprint (2–3 GB RAM)
Through innovations like MatFormer and Per-Layer Embeddings, the model runs complex tasks under 3 GB of RAM—even though its raw parameters are 5–8 B. - Multimodal flexibility in one model
It natively handles multiple inputs—text, vision, audio, and soon video—with seamless interleaving. - Privacy‑first local execution
All data processing occurs on-device, reducing latency, lowering costs, and keeping user data private.
Challenges & Ethics
- On-device privacy risks
While inference is local, deploying a powerful model on-device opens the potential for misuse or leaking proprietary weights—security layers like Trusted Execution Environments may be needed. - Model bias in audio/vision recognition
Like any AI, Gemma 3n can reflect biases or misclassify content in speech or images; this requires careful monitoring. - Fine‑tuning & regulation complexity
Updating or customizing the model on-device demands developer skill and may trigger regulatory concerns around sensitive data. - Energy consumption on mobile hardware
Running intense tasks on-device still taxes battery life—especially for longer audio or video workloads.
E‑E‑A‑T Note
Google applies responsible AI practices—including rigorous safety evaluations, alignment with AI ethics, and strong data governance—for open models like Gemma 3n.
Getting Started: Code & Resources
Ready to try out Gemma 3n? Below is a simple, modular setup that you can use right away. We’ll walk through:
Install the helper library
We’re using a tiny wrapper called kagglehub to fetch model files directly from Kaggle:
pip install kagglehub transformers torchLoad the model once
import kagglehub
from transformers import AutoProcessor, AutoModelForImageTextToText
import torch
DEVICE = "cuda" # or "cpu" if you don’t have a GPU
# Download and cache the model
GEMMA_PATH = kagglehub.model_download("google/gemma-3n/transformers/gemma-3n-e2b-it")
processor = AutoProcessor.from_pretrained(GEMMA_PATH)
model = AutoModelForImageTextToText.from_pretrained(
GEMMA_PATH,
torch_dtype=torch.float32,
device_map=DEVICE,
low_cpu_mem_usage=True
)Optional: Right after loading, you can apply dynamic quantization to shrink the model in memory:
from torch.quantization import quantize_dynamic
model = quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)
Common generate function
This helper will handle prompts of any type—text, audio or images—using the standard chat RPC.
def generate_response(messages,
temperature=0.7,
top_k=50,
top_p=0.9,
max_tokens=512):
"""Core inference logic for all use cases."""
# Tokenize and package the chat inputs
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
).to(DEVICE, dtype=torch.float32)
input_len = inputs["input_ids"].size(-1)
# Run generation in torch’s inference mode
with torch.inference_mode():
outputs = model.generate(
**inputs,
max_new_tokens=max_tokens,
temperature=temperature,
top_k=top_k,
top_p=top_p,
do_sample=True,
disable_compile=True
)
# Decode just the new tokens (skip the prompt)
return processor.batch_decode(
outputs[:, input_len:],
skip_special_tokens=True,
clean_up_tokenization_spaces=True
)[0]Ready‑to‑use wrappers
def text_chat(prompt, **kwargs):
"""Simple text‑only chat."""
messages = [{"role": "user", "content": [{"type": "text", "text": prompt}]}]
return generate_response(messages, **kwargs)
def transcribe_audio(audio_path, prompt="Transcribe this audio clip.", **kwargs):
"""Upload an audio file and get a word‑for‑word transcript."""
messages = [{
"role": "user",
"content": [
{"type": "audio", "audio": audio_path},
{"type": "text", "text": prompt}
]
}]
return generate_response(messages, **kwargs)
def describe_image(image_path, prompt="Describe this image in detail.", **kwargs):
"""Send an image and get back a rich textual description."""
messages = [{
"role": "user",
"content": [
{"type": "image", "image": image_path},
{"type": "text", "text": prompt}
]
}]
return generate_response(messages, **kwargs)Other ways to run Gemma 3n
If you prefer a hosted or offline solution, you can also access Gemma 3n through:
- Ollama – Lightweight local serving with an Ollama CLI plugin
- Hugging Face – Hosted inference API and
transformersintegration - MLX – Model catalog for easy deployment in Kubeflow/MLflow
- LM Studio – Mac/Windows desktop app for interactive prompting
- Google AI Studio – Paid managed hosting with GPU support
With this setup in hand, you can swap in Gemma 3n for anything from chatbots and transcription to image captioning—all with just a couple of lines of code.
Conclusion
Gemma 3n represents a big leap forward in on‑device AI. By packing powerful text, audio, and vision understanding into a model that fits comfortably in 2–3 GB of RAM, Google has made it possible to build fast, private, and offline‑capable apps on phones, laptops, and embedded systems. Whether you’re transcribing a meeting in real time, analyzing photos without an internet connection, or creating a multimodal chatbot that sees and hears, Gemma 3n delivers near state‑of‑the‑art performance without the cloud.
For developers, this means lower latency, stronger privacy protections, and the freedom to innovate in settings where connectivity or bandwidth are limited. As more tools and libraries add support—like the Hugging Face Transformers integration, Ollama CLI, and LM Studio—you’ll find it easier than ever to experiment with Gemma 3n in your own projects.
Ready to get started? Check out the example code above, grab the model weights, and start building. The future of AI isn’t in the cloud—it’s in your hands, on your device, and it’s already here with Gemma 3n.
Prakrati Pawar July 1, 2025
Hello