
LLM memory is the unsung backbone of practical, user-centric AI products. Out of the box, large language models are stateless: each prompt is processed in isolation, which is fine for one-off queries but insufficient for systems that should remember user preferences, past tasks, or domain facts over time. Designers and engineers building conversational agents, personal assistants, and agentic workflows need durable, accessible memory layers that bridge short-term context windows and long-term knowledge.
This article explains what each memory type is, how it maps to cognitive science concepts (like working vs. episodic memory), and how these memory modes appear in real LLM systems — from context stacking and retrieval-augmented generation (RAG) to memory layers and read-write modules. I analyzed top developer docs, vendor research, and recent papers to extract practical patterns and trade-offs (e.g., latency, token cost, privacy). You’ll get a structured taxonomy, engineering patterns, design checklists, examples (LangChain, Pinecone, Mem0, RET-LLM), and a short roadmap to start implementing robust memory in your LLM systems.
Table of Contents
A taxonomy of memory types in LLM systems
Designing memory for LLMs starts with a clear taxonomy — what do we mean by memory? Recent surveys and papers propose a pragmatic four-part taxonomy that mirrors cognitive science: parametric, contextual (working), external, and episodic/procedural. This taxonomy is useful for system design because each type has different location, persistence, write/read paths, and controllability. arXiv
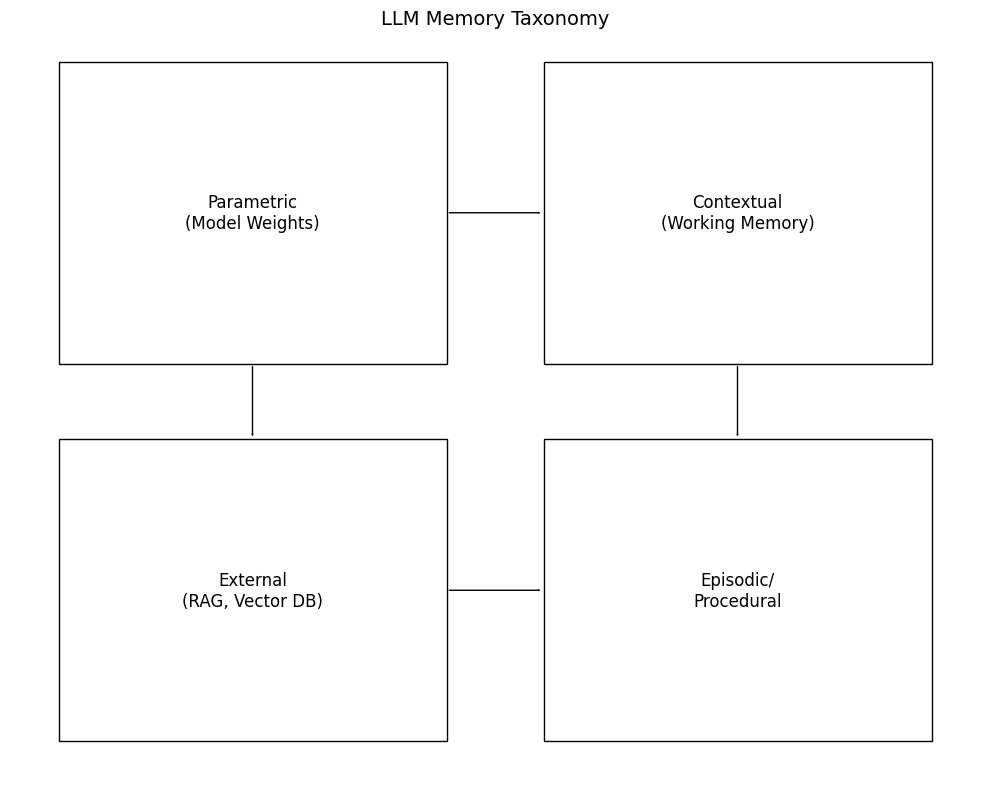
Parametric memory = knowledge stored in the model’s parameters. It’s written during pretraining and fine-tuning and is fast to access (no retrieval), but difficult to update and expensive to retrain. This is analogous to long-term semantic memory in humans: broadly true facts encoded in weights. Use cases: factual grounding, static knowledge where updates are infrequent.
Contextual (working) memory = the context window, i.e., the tokens passed in the prompt. This is ephemeral and session-scoped; it’s like working memory in cognition — high bandwidth but short lived. Engineering pattern: include recent messages + instruction templates in prompts; but this is limited by token budgets and becomes costly for long sessions. LangChain docs and guides highlight conversation chains and session scopes as short-term memory patterns. LangChain Docs
External memory = retrieval stores such as vector databases, key-value stores, or document stores that an application queries to fetch relevant facts before composing prompts (RAG). External memory is controllable, updatable, and supports large scale persistence without bloating the prompt. This is a staple in production systems (Pinecone + LangChain examples). Pinecone
Episodic / procedural memory = structured session histories, action logs, and user-specific timelines. This supports continuity (e.g., “what did the user ask last week?”) and procedural recall (how to re-run multi-step tasks). Tools like MemoryBank or Mem0 implement patterns for consolidating session data into prioritized, searchable memories. AAAI Open Access
Why this matters for system design: each memory type imposes different constraints on cost, latency, updateability, and privacy. For example, parametric memory is fast but hard to fix when incorrect; external memory is flexible but adds retrieval latency and operational complexity. A best practice is hybrid memory: keep frequently used facts in a retriever + cache important session state into summaries passed in context — giving you the strengths of both worlds.
Mapping LLM memory to cognitive science
Cognitive science offers useful analogies:
sensory buffer → context window, working memory → prompt context, semantic memory → parametric weights, and episodic memory → stored conversation logs.
Recent surveys explicitly map human memory taxonomy to LLM memory types, showing how consolidation (summarization) and forgetting (eviction) become engineering design levers. arXiv
Working memory analogy (context window): Humans keep limited items active; LLMs have a finite context window (512–100k+ tokens depending on model/design). Systems must therefore choose what to keep «in mind»: immediate messages, recent tasks, or the latest step in a workflow. Techniques such as message rolling windows, importance scoring, and systematic summarization mirror human rehearsal strategies to keep relevant info in working memory. LangChain docs provide practical tools for thread-scoped state, showing how to keep session scope small and relevant. LangChain Docs
Semantic memory analogy (parametric): Encoded facts in weights are like learned general knowledge. Cognitive models emphasize that semantic knowledge is slow to form but stable — just like model parameters created during long pretraining. Engineers must decide when to fine-tune vs use retrieval: fine-tuning is suitable for broad, stable domain shifts; retrieval + contextualization is better for fast-changing facts.
Episodic memory analogy: Humans store event sequences with timestamps and context; for LLM systems, storing timestamped conversations or events lets agents reference past episodes (personalization, follow-ups). Systems must implement indexing strategies (embedding + metadata) to find relevant episodes efficiently. Research prototypes show this improves personalization and reduces repetition. AAAI Open Access
Consolidation and forgetting: Cognitive consolidation compresses experiences into stable knowledge. In LLM systems this maps to periodic summarization (compress chat logs into short summaries stored externally) and memory pruning/eviction strategies. Vendors like Mem0 and memory engines propose automated consolidation to reduce token costs while preserving utility. mem0.ai
Unique insight: Treating memory as transformable data (raw events → summaries → parametric updates) makes update strategies explicit: you can pipeline write → consolidate → (optionally) fine-tune. Building this pipeline gives product teams deterministic control over what becomes “part of the model’s knowledge” versus what stays in a queryable store.
Memory operations: read, write, update, delete, inhibit
A memory system must implement CRUD-like semantics for memories but extended with inhibit (forget) and consolidate operations. Recent literature frames memory as a write → read → inhibit/update chain — understanding these paths is crucial for governance, correctness, and latency control. arXiv
Write paths
- Pretraining writes write globally to parametric memory (weights).
- Fine-tuning writes perform targeted parametric updates — slow and heavy.
- Runtime writes persist data to external stores (vector DB, SQL, object store) or session logs. Open proposals (RET-LLM) explore read-write modules integrated with model inference to allow dynamic writes with structured triplets. arXiv
Read paths
- Contextual reads are simply passing the right tokens in the prompt.
- Retriever reads involve nearest-neighbor search in embedding space (vector DB), followed by re-ranking and summarization. This is the backbone of RAG workflows. Pinecone + LangChain guides demonstrate practical retrieval loops that prepend retrieved passages to prompts. Pinecone
Update / Inhibit / Delete
- Systems must support editing memories (e.g., user changes preference), redaction (privacy requests), and automated eviction (stale info). A good design separates mutable metadata (e.g., timestamps, priority) from immutable event logs for auditability. Tools and frameworks emphasize providing user controls (view/edit/delete) and audit trails. GitHub
Operational notes
- Write frequency vs cost: High write frequency into vector DB is fine, but re-embedding and re-indexing at scale can be expensive.
- Consistency: Many systems tolerate eventual consistency for memory stores — but critical workflows (medical notes, legal) must ensure strict update semantics.
- Isolation & namespaces: Use namespaces for multi-tenant isolation and per-user privacy.
Case example: RET-LLM and M+ prototypes show co-trained retriever + memory modules that enable efficient read/write updates during inference, improving temporal QA tasks where facts change frequently. arXiv
Memory architectures & mechanisms (tech stack)
At engineering level, memory systems are stacks of components that coordinate to provide durable, relevant context to the model. Typical architecture layers:
- Event capture & ingestion — collects raw events (messages, user actions, API calls).
- Preprocessing & extraction — NLP pipelines extract entities, embeddings, and salient triplets.
- Storage & indexing — vector DBs (approximate nearest neighbor indexes), SQL for structured metadata, object stores for documents. Pinecone and open tools are commonly used. Pinecone
- Retrieval & ranking — embedding search followed by re-rank or cross-encoder scoring to select best candidates.
- Consolidation module — summarizes or compresses old events into compact memories (e.g., periodic summarization). Mem0 and MemoryBank give concrete examples of memory consolidation to reduce token costs and improve relevance. mem0.ai
- Controller / policy layer — decides when to write to parametric memory (fine-tune), when to persist externally, and what to evict. This is increasingly agentic: policies can be rule-based or learned.
RAG (retrieval-augmented generation) is the most common pattern in production: embed query → nearest neighbor retrieval → optionally summarize → include in prompt → generate. RAG improves factuality and keeps models small by outsourcing knowledge storage. Developer guides show how to wire RAG with LangChain and Pinecone for conversational assistants. LangChain
Memory engines & services: Products such as Mem0 and open projects like Memori provide higher-level memory services (indexing, consolidation, prioritization, personalization) that sit between your app and model. They claim real gains on accuracy and cost by better memory management. Use them when you want an out-of-the-box memory layer that handles lifecycle concerns. mem0.ai
Unique perspective: Think of memory as queryable context fabric rather than static logs. Designing policies and consolidators that transform raw events into prioritized, compressed memory objects will pay larger dividends than more compute or larger models — especially for personalization and long-horizon tasks.
Design patterns & trade-offs
Pattern 1 — Hybrid memory (best practice): Keep a short, high-precision working set in context, a mid-term cache for recent salient memories (summaries), and a long-term external store for permanent records. This reduces prompt size while preserving continuity. LangChain examples show conversation chains + long-term memory stores. LangChain Docs
Pattern 2 — Summarize & compress: Periodically condense long dialogues into a short “user profile” or “task summary” to store as a single memory object. This reduces token costs and improves retriever precision. Vendors like Mem0 emphasize consolidation as core to achieving token savings. mem0.ai
Pattern 3 — Prioritized retention & TTLs: Assign importance scores and time-to-live (TTL) values to memories, evict low-value items automatically, keep high-value items long. This mimics forgetting and optimizes storage.
Tradeoffs:
- Latency vs accuracy: External retrieval adds network roundtrips; local caching or parametric encoding is faster but less updatable.
- Cost vs freshness: Frequent re-indexing keeps memory fresh but increases storage and compute bills.
- Privacy vs personalization: More detailed memory improves personalization but raises privacy and compliance needs. Build user controls and redaction mechanisms.
Practical rule: Start with a simple RAG + summarization loop; measure personalization lift and token cost, then layer in more advanced consolidation or a memory engine if benefits justify complexity. Pinecone + LangChain is a low-friction starting stack. Pinecone
Privacy, governance & user controls
Memory systems increase product value—but also responsibility. Users expect control, and regulators increasingly require data rights (view, edit, delete). Best practices:
- Consent & transparency: Clearly tell users what is being remembered and why. Provide UI to view memories. Memori and LangChain examples emphasize user-facing memory controls. GitHub
- Deletion & redaction: Implement hard delete for user requests and soft redaction for flagged content. Keep immutable audit logs separate from user-visible memories to respect provable deletions while retaining operational traces.
- Access control & encryption: Namespace memories per user and enforce role-based access; encrypt sensitive data at rest.
- Explainability: Provide provenance — when a memory is used, attach metadata (source, timestamp, relevance score) so outputs can be traced back. This reduces hallucination risk and improves debugging. Vendors often expose provenance id with retrieved chunks. Pinecone
Regulatory note: For privacy-sensitive domains (healthcare, finance), prefer on-premise or customer-owned storage and minimal retention policies. The memory policy should be part of product compliance reviews.
Evaluation: metrics & tests
Measuring memory effectiveness requires tests for recall, relevance, accuracy, and user value. Common metrics:
- Retrieval recall@k for retrieval accuracy (did the retriever return relevant memory?).
- Downstream task improvement (e.g., personalization accuracy, task success rate). Many vendors report % accuracy lift when memory is present (Mem0 research claims significant gains). mem0.ai
- Hallucination reduction rate — measure decrease in factual errors when RAG + memory is enabled. IBM research shows memory augmentation can reduce hallucinations and improve flexibility. IBM Research
- Latency & token cost — measure p95 latency of retrieval+generation and token costs per session.
- User satisfaction / retention — A/B test memory-enabled vs stateless agents; personalization improvements often translate to higher retention.
Testing approaches: synthetic benchmarks (temporal QA), longitudinal user studies, and offline simulations with recorded sessions. Research papers (MemoryBank, RET-LLM, M+) use specialized temporal QA datasets to show benefits of read-write memory. AAAI Open Access
Case studies & examples
LangChain + Pinecone: A common stack—LangChain manages conversation chains and memory abstractions; Pinecone provides vector indexing and retrieval. Tutorials show how to wire conversational memory for continuity and personalization. LangChain
Mem0: A vendor memory layer that claims consolidation, compression, and prioritized storage produce large accuracy and token-cost benefits. Mem0 positions itself as a scalable memory layer for production agents. Use case: personalization across multi-session assistants. mem0.ai
RET-LLM & M+ (research prototypes): These papers propose co-trained read-write memory modules that allow LLMs to update memories during inference and retrieve them later — improving performance on temporally sensitive tasks. They are blueprints for production read-write systems. arXiv
MemoryBank / AAAI: Demonstrates continuous memory updates and personalization in dialog agents, highlighting design patterns for evolving user models. AAAI Open Access
Practical takeaway: Start with RAG + summarized session memory. If you need dynamic updates and high personalization at scale, consider memory engines or co-trained memory modules.
Best practices checklist for production
- Start simple: implement RAG + session summarization. LangChain
- Use namespaces and RBAC for per-user separation. LangChain Docs
- Consolidate long dialogs into short summaries periodically to reduce tokens. mem0.ai
- Add provenance metadata to every retrieved chunk. Pinecone
- Implement user controls: view/edit/delete memories. GitHub
- Monitor metrics: recall@k, task success lift, hallucination rate, latency. mem0.ai
- Plan for compliance: data residency, encryption, retention policies.
- Adopt a hybrid memory architecture and budget for operational cost of re-indexing.
Open research directions & future-proofing
Active research areas include co-trained read-write memory modules, memory consolidation algorithms that mimic human forgetting, scalable on-device memory, and memory safety (poisoning prevention). ArXiv surveys and recent papers map a broad research agenda linking cognitive insights to memory system design. arXiv+1
Future proofing tips: design modular memory layers (swap vector DBs, change retriever models), expose provenance, and keep model updates as separate staged operations (don’t bake volatile facts into parametric weights unless necessary).
Quick Takeaways
- LLM memory is multi-modal: parametric (weights), contextual (prompt), external (vector DB), episodic (logs). arXiv
- RAG + summarization is the pragmatic starting point for durable memory. Pinecone
- Consolidation (summaries) reduces token cost and improves retriever precision — a core operational pattern. mem0.ai
- Design tradeoffs: latency vs accuracy, privacy vs personalization — plan policies & namespaces. LangChain Docs
- Measure uplift with retrieval recall, task success, hallucination reduction, and user retention metrics. mem0.ai
Conclusion
Memory transforms an LLM from a stateless text generator into a continuity engine that can personalize, follow up, and act across time. For system designers, the challenge is less about inventing new language models and more about building robust memory layers that balance accuracy, latency, cost, and privacy. The practical path forward is layered: start with contextual + external memory (RAG), add summarization/consolidation to control token costs, and evolve toward co-trained read-write modules or memory engines if you need stronger dynamic updates or higher personalization. Research and vendor solutions (e.g., RET-LLM prototypes, MemoryBank, Mem0) provide blueprints for read/write and consolidation strategies, and developer ecosystems (LangChain, Pinecone, Memori) make initial implementation accessible. arXiv
Implementing memory responsibly means pairing functionality with user controls, audit trails, and clear retention policies. If you’re building an assistant, start simple with RAG + a summarized session store; instrument the system, measure user value, then iterate. Memory is not a single feature — it’s a platform capability that, when designed thoughtfully, becomes the difference between a transient bot and a trusted, long-term AI companion.
Call to action: Try a small RAG + summary prototype with a vector DB and measure task success lift over a controlled cohort — then decide whether to adopt a memory engine or co-trained memory module.
FAQs
Q1: What is the best first step to add memory to an LLM-based app?
A1: Start with retrieval-augmented generation (RAG) using a vector database (e.g., Pinecone) and keep a short session summary in the prompt — this balances effort and benefit. Pinecone
Q2: How does parametric memory differ from external memory?
A2: Parametric memory is baked into model weights (pretraining/fine-tune) and is fast but hard to update; external memory is stored in databases and is updatable and auditable. arXiv
Q3: How do I keep memory from leaking private data?
A3: Use namespaces, encryption, strong access controls, and implement deletion/redaction UI. Keep audits separate from user-visible memories. LangChain Docs
Q4: When should we fine-tune vs. use retrieval?
A4: Fine-tune for stable, broad domain knowledge; use retrieval for fast-changing facts or per-user personalization because it’s cheaper and instantly updateable. arXiv
Q5: Which metrics show memory is working?
A5: Measure retrieval recall@k, downstream task success rate, hallucination reduction, token cost, and user retention lift. mem0.ai
Engagement / Social CTA
If you found this breakdown useful, please share it with a teammate who’s building an LLM product. I’d love feedback — which memory pattern are you planning to try first: RAG + summaries, or a memory engine like Mem0/Memori? Reply below and I’ll suggest concrete next steps for your choice.
References (authoritative sources)
- Wu, Y. et al., From Human Memory to AI Memory: A Survey on Memory Mechanisms in the Era of LLMs. arXiv (2025). arXiv
- LangChain — Long-term Memory / Memory overview and docs. LangChain
- Mem0 — Memory layer for AI apps; research & product pages. mem0.ai
- Pinecone — Conversational Memory for LLMs with LangChain (developer guide). Pinecone
- IBM Research — How memory augmentation can improve large language models (research blog). IBM Research